Gráficos
O LabIFSC2 precisa implementar algumas funções para converter um objeto Medida em um float, para que se possa criar gráficos em bibliotecas como o Matplotlib e Seaborn. Nesta seção, continuaremos o exemplo do campo magnético em função da distância da seção Arrays.
Nominais
Para obter os valores nominais de um array numpy de medidas, basta usar a função nominais(array_medida, unidade):
campo_magnético=arrayM([250,150,110,90,70,60,55,40,25,20],'muT',1)
print(nominais(campo_magnético,'muT'))
#[250. 150. 110. 90. 70. 60. 55. 40. 25. 20.]
Incertezas
De maneira análoga, podemos também pegar as incertezas com incertezas(array_medida, unidade):
campo_magnético=arrayM([250,150,110,90,70,60,55,40,25,20],'muT',1)
print(incertezas(campo_magnético,'muT'))
#[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
Dispersão com barras de erro
Eis um exemplo simples de como fazer um gráfico de dispersão com erros tanto em x quanto em y, basta usar a função do matplotlib plt.errorbar, nominais e incertezas. (Eu modifiquei as incertezas do exemplo para serem mais visíveis)
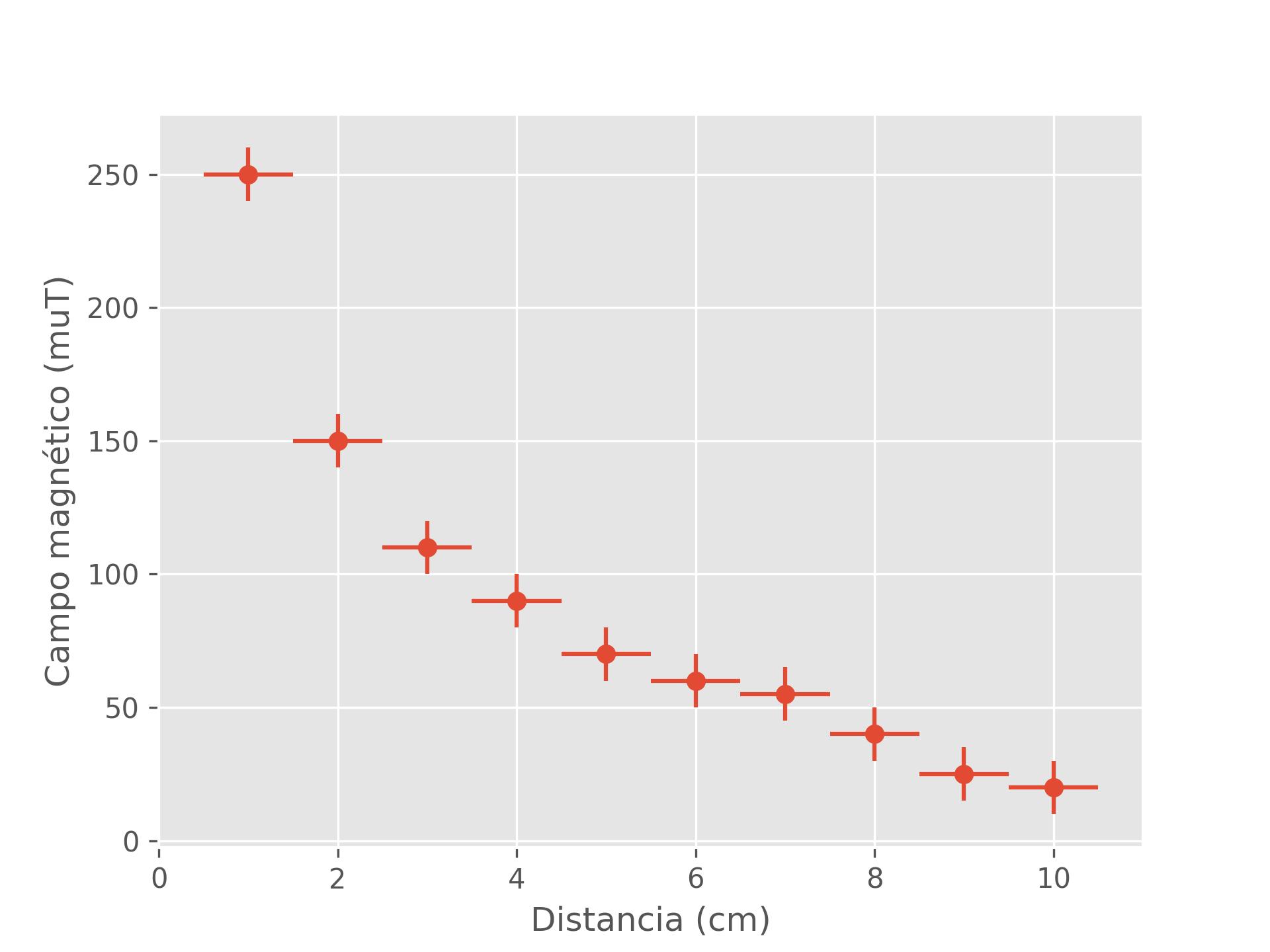
import matplotlib.pyplot as plt
campo_magnético=arrayM([250,150,110,90,70,60,55,40,25,20],'muT',10)
distancias=linspaceM(1,10,10,'cm',0.5)
unidade_x='cm'
unidade_y='muT'
plt.style.use('ggplot')
plt.errorbar(
x=nominais(distancias,unidade_x),
y=nominais(campo_magnético,unidade_y),
xerr=incertezas(distancias,unidade_x),
yerr=incertezas(campo_magnético,unidade_y),
fmt='o')
plt.xlabel(f"Distancia ({unidade_x})")
plt.ylabel(f"Campo magnético ({unidade_y})")
Repare que as unidades são variáveis no código que podem ser modificadas rapidamente.
Curva Min/Max
As funções curva_min e curva_max são utilizadas para calcular a curva teórica considerando as incertezas nos parâmetros encontrados durante a regressão dos dados
Essas curvas são as bandas de confiança do fitting. Existem várias maneiras de fazê-las, mas basicamente estamos aproximando cada ponto amostrado como uma distribuição gaussiana e calculando o intervalo de confiança dessa gaussiana.
Resumidamente, estamos pegando abaixo e acima do fitting. Pela hipótese de distribuição gaussiana1, os dados devem cair nesse intervalo com 95% de certeza.
Essas funções podem ser aplicadas diretamente em uma regressão,voltando para o exemplo da lei de kepler, vemos que o fitting tem pouca incerteza, visto que as curva min e max são bastante próximas
print(curva_min(fitting,'years')[0:5])
#[0 0.16563505 0.46786682 0.85881466 1.3214152 ]
print(curva_max(fitting,'years')[0:5])
#[0 0.16875531 0.47653809 0.87467204 1.34582704]
Essas funções também podem ser aplicadas diretamente em arrays de medidas
curva=linspaceM(0,5,6,'m',0.1)
print(curva_min(curva,'m'))#[-0.2 0.8 1.8 2.8 3.8 4.8]
print(curva_max(curva,'m'))##[0.2 1.2 2.2 3.2 4.2 5.2]
print(curva_min(curva,'m',4))#[-0.4 0.6 1.6 2.6 3.6 4.6]
print(curva_max(curva,'m',4))#[0.4 1.4 2.4 3.4 4.4 5.4]
Curva teórica com erro
Regressões de dados inevitavelmente apresentam incertezas nos parâmetros encontrados. Podemos representá-las usando as funções curva_min e curva_max, que calculam a curva teórica .
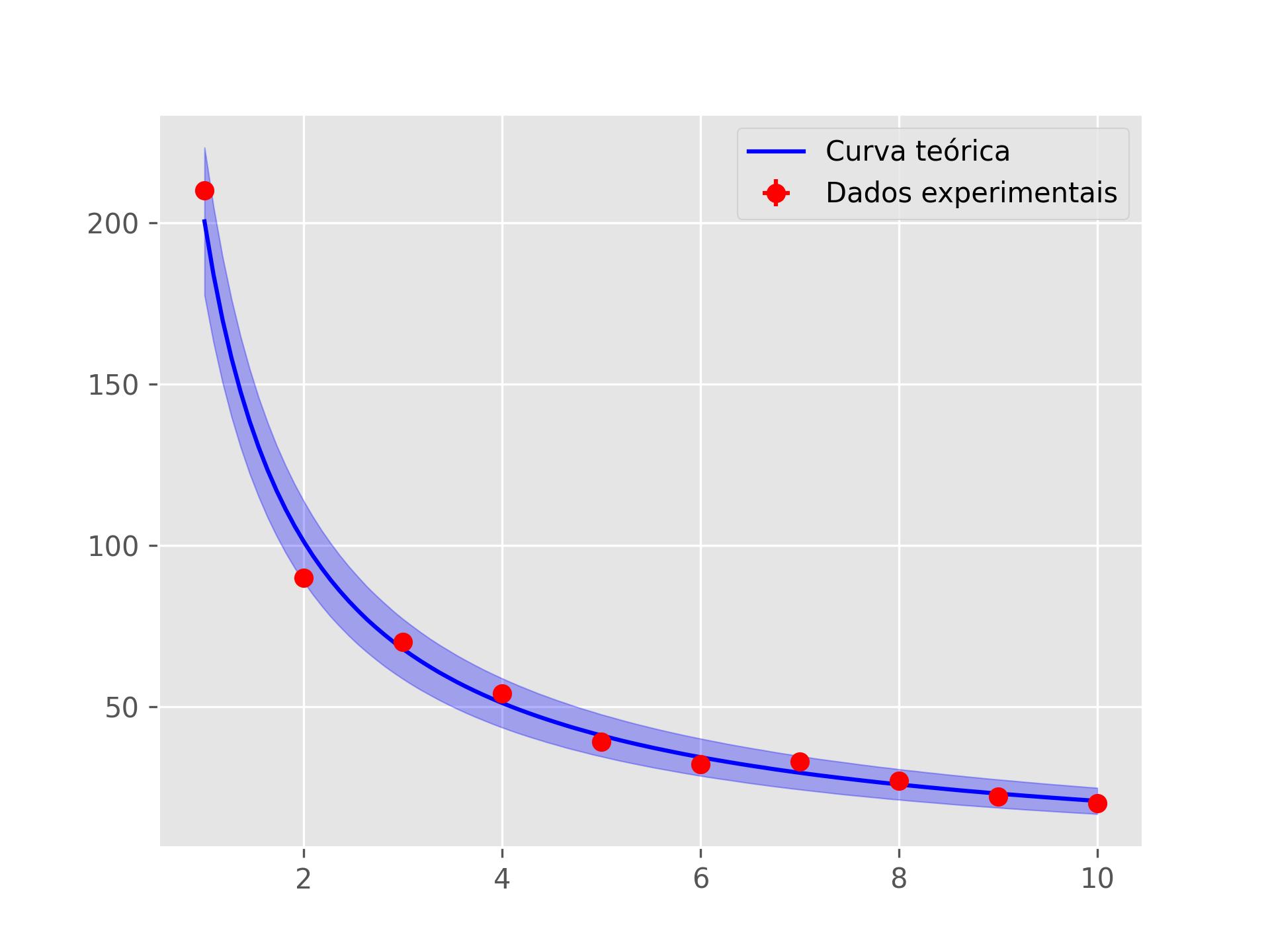
x=linspaceM(1,10,100,unidade_x,0)
plt.plot(
nominais(x,unidade_x),
fitting.amostrar(x,unidade_y),
color='blue',
label="Curva teórica")
plt.fill_between(
x=nominais(x,unidade_x),
y1=curva_min(fitting,unidade_y),
Isso é algo pessoal, mas como as funções do matplotlib recebem vários argumentos
verbosos, eu recomendo usar um tipo de indentação chamada Hanging indentation, onde cada argumento ocupa uma linha de código. Assim, o código fica mais legível (na minha opinião) e menos horizontal.
-
Se a biblioteca trabalha com distribuições estatísticas arbitrárias, por que fazer essa hipótese? Basicamente, cada chamada da função
intervalo_de_confiancapara uma distribuição arbitrária é de complexidade, então calcular ela em centenas ou milhares de pontos é inviável. ↩