Regressão prática
Tipos de regressão
Temos 4 tipos de regressões possíveis:
regressao_linear(x_medidas, y_medidas)regressao_polinomial(x_medidas, y_medidas, grau)regressao_exponencial(x_medidas, y_medidas, base)regressao_potencia(x_medidas, y_medidas)
O resultado é armazenado respectivamente em um objeto MPolinomio, MExponencial e MPotencia. Essas classes são todas herdadas de uma mesma classe abstrata, então elas compartilham a mesma interface. Na prática, essas classes são irrelevantes, você provavelmente só vai pensar que está lidando com uma regressão.
Warning
Lembre-se que, para regressões exponenciais, todos os valores de y precisam ser positivos. No caso da regressão de lei de potência, os valores de x também precisam ser positivos. Além disso, um valor pode não ser negativo, mas devido à incerteza associada, ele pode assumir valores negativos.
Calcular Regressão
Polinomial
Não há muito segredo nessa parte, as funções recebem os arrays de medidas em e . É importante salientar que essas funções recebem Medidas, isso porque queremos os parâmetros da regressão tendo unidades. Como exemplo, estamos imaginando aqui um objeto em queda livre vertical, nós registramos a sua posição na vertical em função do tempo e queremos encontrar a melhor parábola que se encaixa nos dados.
tempos=linspaceM(0,5,10,'s',0.01)
alturas=arrayM([0,1.4,6,13,24,36,52,70,95,120],'m',0.1)
#y=y0 + vt + 1/2gt²
parabola=regressao_polinomial(tempos,alturas,2)
print(parabola)#MPolinomio(coefs=[(4,9 ± 0,1) m/s², (-8 ± 7)x10⁻¹ m/s, (4 ± 7)x10⁻¹ m],grau=2)
a,b,c=parabola
print(f"gravidade {a*2}") #(9,9 ± 0,3) m/s²
print(f"velocidade inicial {b:E0}") #(-0,8 ± 0,7) m/s
print(f"altura inicial {c:E0}") #(0,4 ± 0,7) m
polinomio.a, polinomio.b etc. (seguindo a convenção de que a é o coeficiente de maior grau), ou utilizando a técnica de unpacking do Python, igualando os coeficientes ao polinômio (igual ao unpacking de uma tupla).
Exponencial
Imagine um experimento em que queremos determinar a meia-vida de um material radioativo. As escalas de massa e tempo são somente ilustrativas. Podemos acessar a constante multiplicativa fazendo exponencial.cte_multiplicativa e o expoente fazendo exponencial.expoente.
tempos=linspaceM(0,10,11,'year',0)
massa=arrayM([1, 4.7e-1 , 2.3e-1 , 1.2e-1 ,
6.23e-2, 3.11e-2 ,1.53e-2 ,7.8e-3 ,
4e-3 ,2e-3 ,1e-3],'kg',0)
exponencial=regressao_exponencial(tempos,massa,base=2)
print(exponencial)
#MExponencial(cte_multiplicativa=(9,3 ± 0,2)x10⁻¹ kg,expoente=(-9,89 ± 0,04)x10⁻¹ 1/a,base=2)
M_0=exponencial.cte_multiplicativa
meia_vida=-1/exponencial.expoente
print(f"{M_0:E0}") #(0,93 ± 0,02) kg
print(f"{meia_vida:E0}") #(1,011 ± 0,004) a
Lei de Potência
Um exemplo clássico de lei de potência é a terceira lei de Kepler, onde o período orbital (T) se relaciona com o raio orbital (R) segundo: A regressão de lei de potência encontra parâmetros como a constante multiplicativa e o expoente a partir de dados experimentais. O exemplo abaixo pega dados da NASA para demonstrar experimentalmente a terceira lei de Kepler. Eu peguei as distâncias em milhas justamente para demonstrar como com o LabIFSC2 você não precisa se preocupar com unidades.
def test_doc_kepler():
#https://nssdc.gsfc.nasa.gov/planetary/factsheet/planet_table_british.html
dados = [
{"planeta": "Mercúrio", "distancia_em_milhoes_milhas": 36.0, "orbita_em_dias": 88.0},
{"planeta": "Vênus", "distancia_em_milhoes_milhas": 67.2, "orbita_em_dias": 224.7},
{"planeta": "Terra", "distancia_em_milhoes_milhas": 93.0, "orbita_em_dias": 365.2},
{"planeta": "Marte", "distancia_em_milhoes_milhas": 141.6, "orbita_em_dias": 687.0},
{"planeta": "Júpiter", "distancia_em_milhoes_milhas": 483.7, "orbita_em_dias": 4331.0},
{"planeta": "Saturno", "distancia_em_milhoes_milhas": 889.8, "orbita_em_dias": 10747.0},
{"planeta": "Urano", "distancia_em_milhoes_milhas": 1781.5, "orbita_em_dias": 30589.0},
{"planeta": "Netuno", "distancia_em_milhoes_milhas": 2805.5, "orbita_em_dias": 59800.0},
]
distancias=np.array([Medida(planeta["distancia_em_milhoes_milhas"],"Mmiles",0) for planeta in dados])
periodos=np.array([Medida(planeta["orbita_em_dias"],"days",0) for planeta in dados])
fitting=regressao_potencia(distancias,periodos)
print(f"{fitting.potencia}")#(1,4979 ± 0,0008)
G=constantes.Newtonian_constant_of_gravitation
pi=constantes.pi
massa_sol=constantes.solar_mass
constante_teorica=np.sqrt(4*pi**2/(G*massa_sol))
print(f"Teórica:{constante_teorica:si}") #(5,4540 ± 0,0001)x10⁻¹⁰ s/m¹⋅⁵
print(f"Experimental:{fitting.cte_multiplicativa:si}") #(5,59 ± 0,03)x10⁻¹ s/m¹⋅⁴⁹⁷⁸⁷
Amostrar
Quando queremos fazer o gráfico de uma curva, precisamos amostrar essa curva em um conjunto de pontos. Para isso, precisamos especificar em que intervalo queremos calcular a curva e em que unidades esse cálculo deve retornar.
amostrar(intervalo_em_x, unidade_y)
No exemplo abaixo, calculamos a nossa regressão (da seção anterior) no intervalo de distâncias dos planetas do sistema solar ([0,30] unidades astronômicas), e pedimos para ele retornar esse resultado em anos.
unidade_x='astronomical_unit'
unidade_y='years'
x=linspaceM(0,30,100,'astronomical_unit',0)
amostragem=fitting.amostrar(x,unidade_y)
print(amostragem)
'''
[ 0. 0.16720236 0.47222204 0.86677871 1.33367488
1.86297947 2.44799678 3.08382118 3.76665199 4.49338729
5.26151605 6.06894605 6.91380503 7.7943936 8.70950132
9.6576868 10.637894 11.64919283 12.6904141 13.76086203
14.85993445 15.98652 17.14022277 18.32023888 19.5262253
20.7574556 22.01355905 23.29377595 24.59812236 25.92529963
27.27589755 28.64912586 30.04414761 31.46106333 32.90057751
34.35997688 35.84108923 37.34286772 38.8647287 40.40618418
41.96774186 43.54918181 45.1495475 46.77017268 48.40808983
50.06563503 51.74134587 53.43456287 55.14656257 56.8772764
58.62478682 60.38904278 62.17100623 63.97154288 65.78745354
67.62110684 69.47029197 71.3363668 73.22010168 75.11830551
77.03396015 78.96476666 80.91117912 82.87311834 84.85279027
86.84630189 88.85517283 90.88003283 92.91871024 94.97238155
97.04086489 99.12494062 101.22470506 103.33573288 105.46558935
107.60652663 109.76323664 111.93360799 114.1169974 116.31588584
118.5287959 120.75651541 122.99423608 125.24817432 127.51591977
129.79705056 132.08950466 134.39633912 136.71555037 139.05241296
141.39816295 143.75757548 146.13123689 148.51706457 150.91355481
153.32539889 155.74978066 158.18744411 160.63534066 163.09497686]
'''
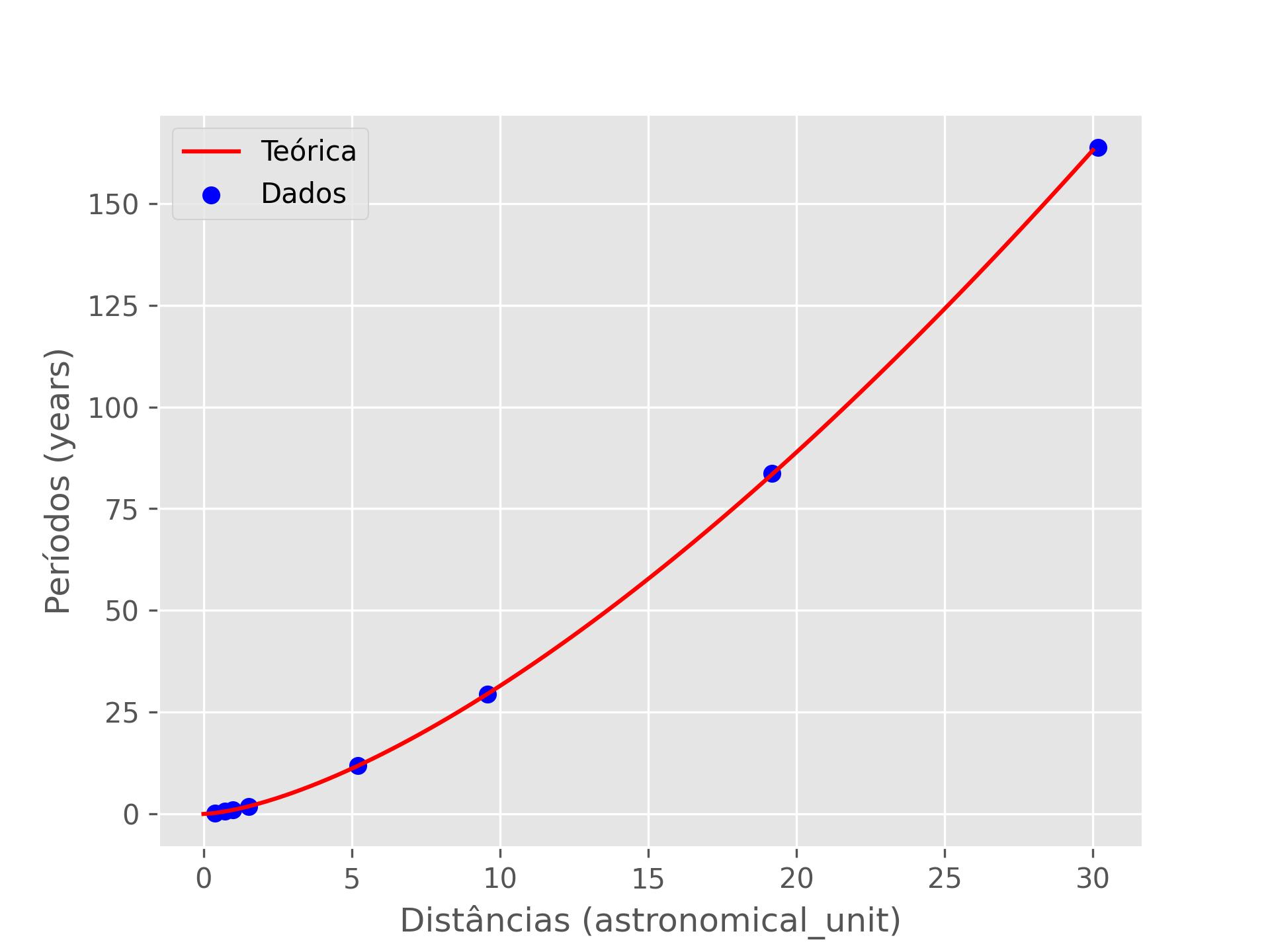
Podemos visualizar esses dados fazendo um pequeno código em matplotlib. Para ler mais sobre gráficos, vá para a seção Gráficos.
plt.style.use('ggplot')
plt.plot(nominais(x,unidade_x),
amostragem,
color='red',
label='Teórica')
plt.scatter(
nominais(distancias,unidade_x),
nominais(periodos,unidade_y),
color='blue',
label='Dados')
plt.xlabel(f'Distâncias ({unidade_x})')
plt.ylabel(f'Períodos ({unidade_y})')
plt.legend()
plt.savefig('docs/images/kepler.jpg',dpi=300)
plt.cla()
Warning
Visto que a biblioteca realiza uma simulação Monte Carlo para cada ponto da curva, usar muitos pontos de amostragem provavelmente irá causar uma lentidão no seu código. No meu notebook, eu tive uma boa experiência amostrando a regressão em 100 pontos. Recomendo você começar com esse valor, se a curva ficar pouco definida, aumente esse valor.
Outra dica: caso tenha que usar a amostragem mais de uma vez, salve o array em uma variável, assim não irá precisar calcular duas vezes. Eu fiz isso no código de exemplo, eu queria printar a amostragem e também usá-la no matplotlib. Isso é uma dica geral de programação, tente sempre calcular as coisas só uma vez.
curva_min e curva_max
Uma função que creio ser muito útil é aplicar curva_min e curva_max em uma regressão. Para que tudo sobre gráficos fique na sua respectiva seção, vá para a seção de gráficos para ler a documentação sobre isso.